Go-Scheduler
翻译自: http://morsmachine.dk/go-scheduler
虽然是13年的一篇文章, 但还是值得一读的.
介绍
Go 1.1版本一个大的改动是由Dmitry Vyukov做的新的调度器. 新的调度器在性能上为go程序并行提供了"戏剧性"的提升(总之是很牛), 然后自己又没别的事情做, 就想着写一写这个新的调度器(或者说思路, 方法, 概念 balabala).
这篇文章中的大部分内容都在这个原始文档中提出了, 这个文档写的很全面, 但是太"技术"了. (我感觉也太技术了, 云里雾里的, 所以作者在这里打算通俗的讲一讲)
关于新的调度器, 你需要知道的都在那篇原始文档里, 但是这篇文章有图~ 所以更清晰一点.
带有调度器的Go运行时(go runtime)需要什么
在我们深入了解调度器之前, 我们需要理解为什么它是必须的. 为什么在操作系统可以帮你调度线程的时候, 你仍然需要一个用户空间下的调度器.
POSIX线程API对于现存的Unix进程模型来说更像是一个逻辑扩展, 于此, 对于线程的控制, 更接近与对进程的控制. 线程拥有其自己的信号标志位, 可以被CPU协同分配, 可以被放进cgroups中管理, 可以被查询其所用的资源等. 这些控件对于go程序调度goroutine来说, 增加了很多无谓的功能和开销, 并且当线程数达到100,000时, 开销会迅速增加.
另一个问题是, 基于Go的语言模型, 系统不能创建可被通知的调度决定(informed scheduling decisions). 比如, Go在垃圾回收时, 需要让所有线程停止, 并且线程使用的内存需要连贯. 这就涉及到, 等到所有正在运行的线程达到一个能使内存连贯的点.
当你有很多线程需要被调度到一个随机的点的时候, 唯一的机会是你要等到大多数线程都达到某个内存连贯的点. 对于Go调度器来说, 它知道哪里的内存是连续的, 所以就能作出这样的决定. 这就意味着, 当gc的时候(stw), 我们只需要等待那些正在被CPU运行的线程即可.
角色一览
对于线程来说, 有三种常见的模型. 一个是 N:1, 即多个用户空间下的线程运行在同一个CPU核心上. 这种模型的优点是, 可以在多个线程间快速的切换上下文, 但缺点也很明显, 无法利用多核系统的优点. 另一个模型是 1:1, 即一个CPU上面只跑一个线程. 这样做的优点是能够利用机器的多个核心, 但缺点与第一种的优点对应: 线程间切换很慢, 因为需要通过操作系统来调度(trap through the OS).
Go语言尝试将以上两种方法组合起来, 使用 M:N 的模型. 也就是 在N个核心上运行M个线程. M和N都是任意的. 这样就能利用以上两种模型的优点: 既能快速切换上下文, 又能将多核都利用起来. 唯一的缺点是, 它增加了调度器的复杂性. (虽然说simple is good, 但复杂真的能解决问题)
为了完成这样一个调度器, Go用了以下三种不同的实体:
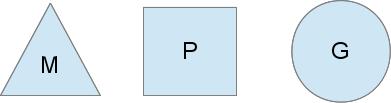
三角形的M代表了一个OS线程; 它是被OS运行的线程, 运行起来也很像一个标准的POSIX线程. 在运行时中, 它被称为M(machine).
圆形的G代表一个goroutine. 包含了栈, 指令指针以及其他对于调度来说的重要信息, 比如阻塞goroutine的一些channel. (额, 在这里需要对goroutine有一个简单的了解, 对比process, thread和goroutine, 知道thread和goroutine的差别, 以及goroutine和thread是怎样产生的, 还要对比fork, clone等一些syscall. 我会抽空写一下三者的差别, 毕竟已经拖了几个月了…) 在运行时中, 它被称为G(goroutine).
正方形代表了调度的内容. 你可以将其视为在一个单一的线程中运行go程序的本地化版本的调度器. 这一部分对于我们把N:1变成M:N是至关重要的. 在运行时中, 它被称为P(processor).
关于这部分的更多内容, 可以看下图:
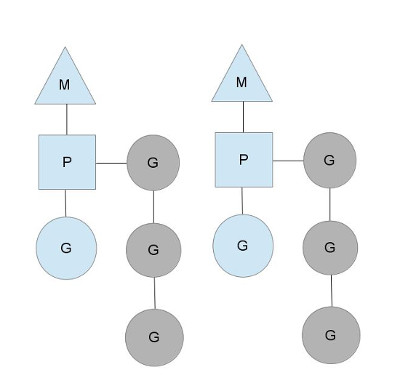
这里我们可以看到, 有两个OS线程M, 每一个都有自己的上下文(P), 也都运行了一个goroutine(G). 为了运行goroutine, 线程必须要有自己的上下文(context).
上下文内容(contexts)的数量, 由启动时候的参数设定, 可以通过环境变量GOMAXPROCS, 也可以通过函数runtime.GOMAXPROCS(). 一般来讲, 这个值在程序运行期间都是不变的. 也正是由于这一点, 在程序运行的时候, 只有GOMAXPROCS这么多的P能够同时运行G. 我们可以利用这个值来调节在电脑上运行的Go进程数量. 比如说, 电脑的CPU有四个核心, 那么就运行四个线程.
上图中, 那些灰色的goroutine是不在运行中的, 但是却准备好被调度. 他们在一个称为runqueues的队列中组织起来. 当有一个go声明的时候(即在程序中有一个 go func()), 就会有一个goroutine被追加到运行队列的尾部. 当context运行到goroutine的调度的时候(比如time.Sleep, 或者runtime.Gosched()), P就会从运行队列中pop一个新的goroutine出来, 设定好堆栈信息, 指令指针(也就是从哪里运行, 可以看下clone的系统调用), 然后就开始跑这个goroutine.
为了避免互斥器的争夺, 每一个context都有自己的本地运行队列. 在之前的go调度器中, 有一个全局的运行队列(runqueue)和一个全局锁(或者叫互斥器)来保护这个队列. 基于此, 线程们常常等待这个mutex解锁. 这样的做法是有点糟糕的, 尤其是当你有一个32核的机器, 你想榨干这台猛兽的每一份资源的时候.
只要context有goroutine运行, go调度器就会保持这种稳定的调度方式. 然而, 有一些情况会改变这种状态.
Who you gonna (sys)call?
你或许会问, 为神马要有一个上下文(context)呢? 我们能不能直接把runqueue应用于线程从而摆脱context? 或许并不能. 我们之所以需要context, 是因为在某些情况下, 我们需要将其交付给其他线程, 如果正在运行的线程因为某些原因需要被阻塞的话.
一个阻塞的例子是, goroutine进行了一次系统调用的时候. 因为一个线程不能同时"阻塞在系统调用上"和"执行”, 所以我们需要将context交付出去, 以保持正常调度.
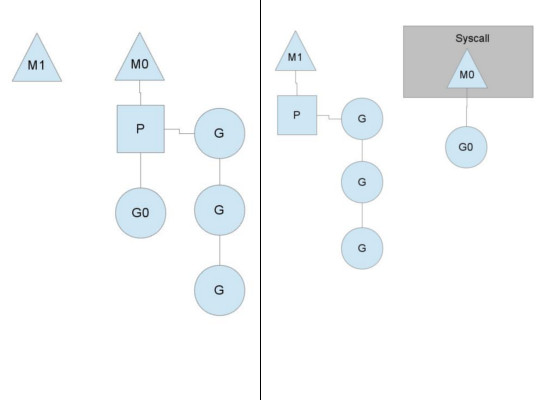
在这里我们可以看到, 有一个线程放弃了自己的context, 以便其他线程可以运行. 调度器会确保有足够的线程来运行context. 在上面的插图中, M1或许就是被创建出来处理这个syscall的, 或者其来自于一个线程缓存(thread cache). 正在执行syscall的线程依旧会保留那个产生syscall的goroutine, 因为从技术层面上看这个goroutine仍在执行, 尽管它在系统层面上是被阻塞的.
当这个syscall执行完毕并返回时, 这个线程就要去获得曾经给出去的context, 以执行剩余的goroutine的代码. 常见的操作是从其他的线程中将context偷出来. 如果搞不定的话, 线程就会将这个goroutine放入全局的运行队列(runqueue)中, 把自己让到线程缓存中, 然后滚去休眠(go to sleep).
全局运行队列是这样一个队列: 他有着一些contexts, 当P的本地runqueue跑完了的时候, 就会从全局运行队列中找活干. Contexts们也会定期检查这个全局队列中的goroutine. 否则的话, 全局队列中goroutine会因为"饥饿"而永不执行.
这种处理syscall的方式就是为什么Go程序会运行多个线程, 即使GOMAXPROCS等于1(即只有一个P). 运行时使用调用syscall的goroutine,从而留下线程。
Stealing work
另一种改变系统稳定状态的情况是, 调度器跑完了context上的goroutine. 这种情景会发生在conetxt的runqueue分配不均衡的情况下. 然后就会导致, 虽然一部分context运行结束了, 但系统中还有一些没干完的活(goroutine). 为了保持代码的持续运行, 一个context会从全局runqueue中拿goroutine来跑, 但如果全局运行队列中也没有goroutine的话, 它也会从别处拿(下文会说是哪儿)
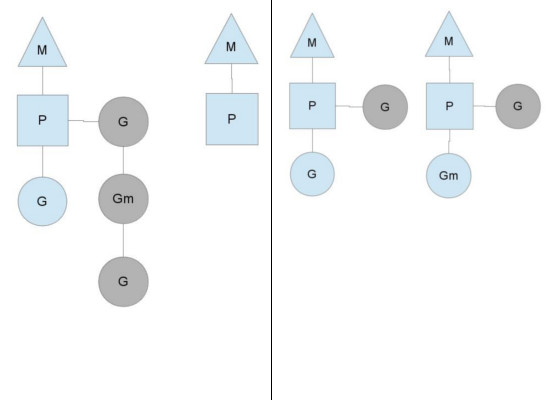
“别处"就是其他的context. 当一个context跑完自己的goroutine时, 如果全局运行队列中也没了goroutine, 那么他就会尝试从别的context的runqueue中偷一部分goroutie来执行. 这就保证了没一个context(或者叫P)都有活干, 从而能够充分利用CPU资源, 让每个线程都动起来.
接下来
对于调度器, 还有其他很多细节, 比如cgo线程, LockOSThread() 函数, 与网络轮询器(network poller)集成等. 这些超出了本文的范围, 但也非常值得学习. 我接下来或许会写一写. 在go的运行库中有很多很多有趣的东西值得研究学习.
By Daniel Morsing