聊一聊转码
iconv
要上密码学了,但是老师发的字幕在我的电脑上有点小问题,因为他们的编码格式是GBK编码 (Windows系统),而我的系统默认的编码是UTF-8,所以会造成有些应用打开的时候出现乱码, 或者干脆啥也没有。
附上两个维基链接:
GBK 编码 https://en.wikipedia.org/wiki/GBK
UTF-8编码 https://en.wikipedia.org/wiki/UTF-8
简而言之,gbk是国产的编码格式,UTF-8是国际化的编码格式。
这就造成了我学习上的一些困扰,那么,该怎样解决这个问题呢?
接下来就请出这篇文章的主角: iconv
简单翻译一下iconv的man手册:
iconv - 把文字从一种格式转换成另一种格式。 如果没有给定输入文件的话,就从标准输入中读取, 如果没有给定输出文件的话,就将转换结果输出到标准输出当中。 默认的编码都是系统的本地默认编码。
iconv [options] [-f from-encoding] [-t to-encoding] [inputfile]…
相关选项:
- -f from-encoding (输入的编码格式,如 -f gbk)
- -t to-encoding (输出的编码格式,如 -t utf8)
如果 **//IGNORE** 跟在输出编码格式后面的话,不能正确转换的文字将会被抛弃,并且转换完成之后
将会打印出错误信息。(PS:不能正确转换的意思是,字符集里没有这个字,也包括那些生僻字哦~也就是说,如果这个编码能够被转换成乱七八糟的生僻字,
那么iconv是可以转换的,因为它“认识”这些生僻字,尽管你不认识。)
如果 **//TRANSLIT** 跟在输出编码后面的话,如果需要并且可能的话,源编码将会被音译为要转换的编码。
这就意味着,如果一个单词不能背转换为相应编码的时候,就会被读音相似,也可以说是拼写相似的单词所代替, 既不能被正确转换,也不能被音译的文字将会以 “?” 表示。
- -l 列出所有已知编码类型
- -c 丢弃那些不能背正确转换的编码,而不是遇到错误时停止。
- -o 后面跟着要输出的文件,例如 -o output.file
- –verbose 当处理多个文件时,打印进度信息到标准错误中。
- -? || –help 显示帮助信息并退出。
- –usage 显示简要用法信息。
- -V 显示版本号。
啊,多么简单的用法。
真的么? 看下面着几个栗子:
这两个文件中分别存放着与文件名相同编码格式的“你好,世界。”,用最基本的iconv命令进行转换,得到的结果如下。
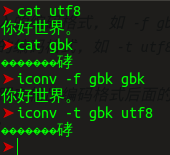
那么,再玩出点花样,把两种格式混合一下会怎样呢?
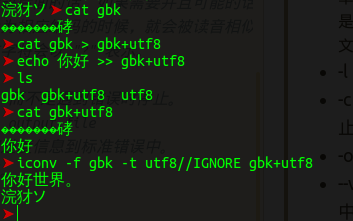
哎呀,//IGNORE 并没有什么卵用,为什么呢?因为,他能被正常转码呀!虽然你不认识那些字,但是计算机认识呀~所以IGNORE选项就没有忽略gbk的编码。
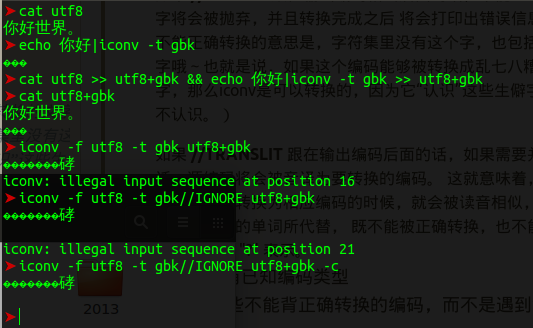
那么这种情况呢?IGNORE选项会忽略掉他也不认识的编码,所以我们就得到了如上的结果。
enca
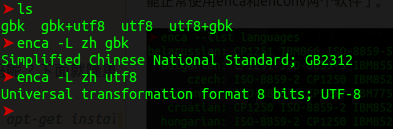
那么有同学就会问了,我该怎样确定输入的到底是那种编码呢?下面就隆重推荐一款软件 enca.
如果你像我一样使用的是Ubuntu系统,那么你只需要sudo apt-get install enca就能正常使用enca和enconv两个软件了。如果不是Ubuntu,那你自己搜一下也能找得到github上的项目代码。
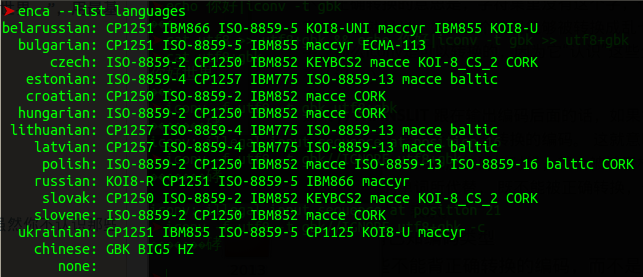
如果需要确定编码格式,则敲打下列命令即可:
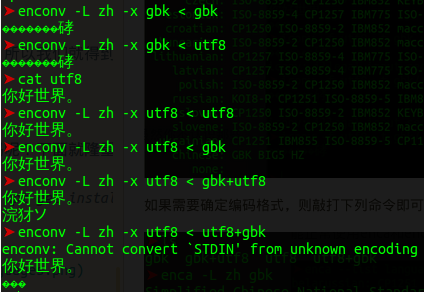
如果需要转码,那么命令会长一些,但是却不必考虑原来的编码。除了混合编码中会遇到些许问题, (所有的转码工具都会遇到的,isn’t it?)总体来说还是不错的转码工具。
recode
无意中我又发现了 recode 这款软件,用起来也是相当简单:
recode gbk..utf8 < inputfile
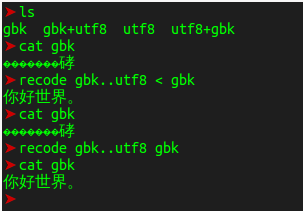
关键在 “<” 重定向符的差别。如果有重定向符号,那就将输出打印出来,如果没有重定向符号而是直接跟着文件名的话,那就会把转换后的结果输出到源文件中,这是比较危险的。
recode -l
显示出所有已知的编码类型,还是相当多的,至少够你用=。=
看了下recode的man手册,相当的丰满,够玩一天的。